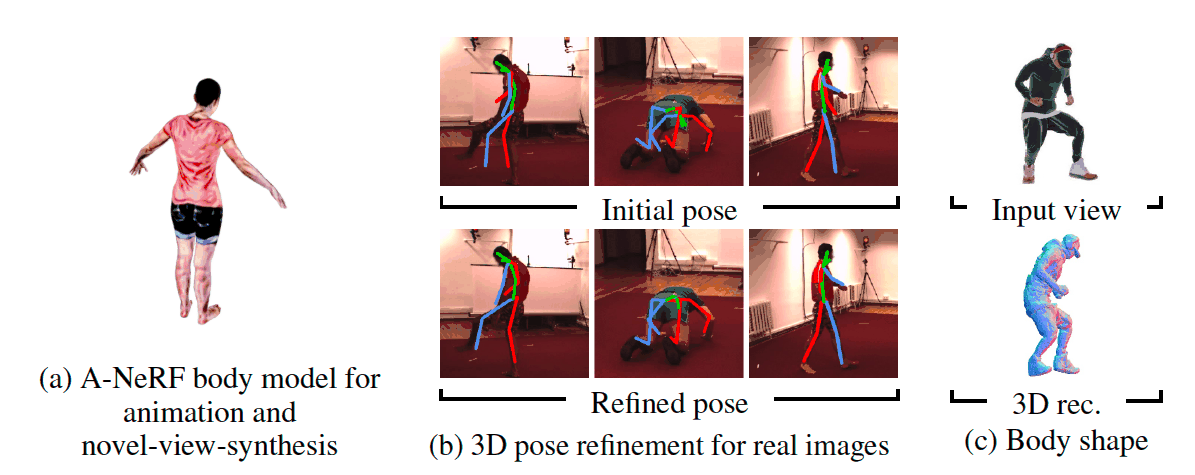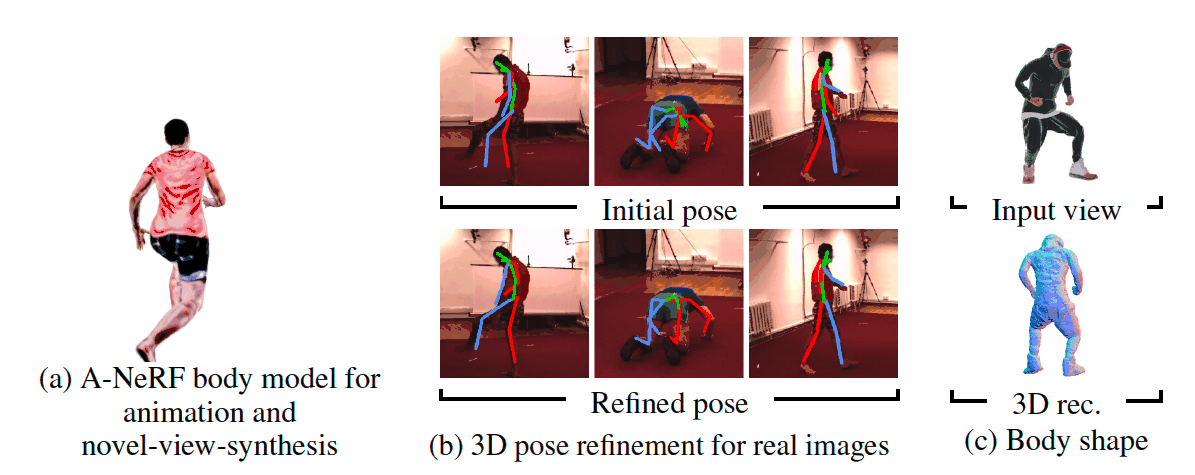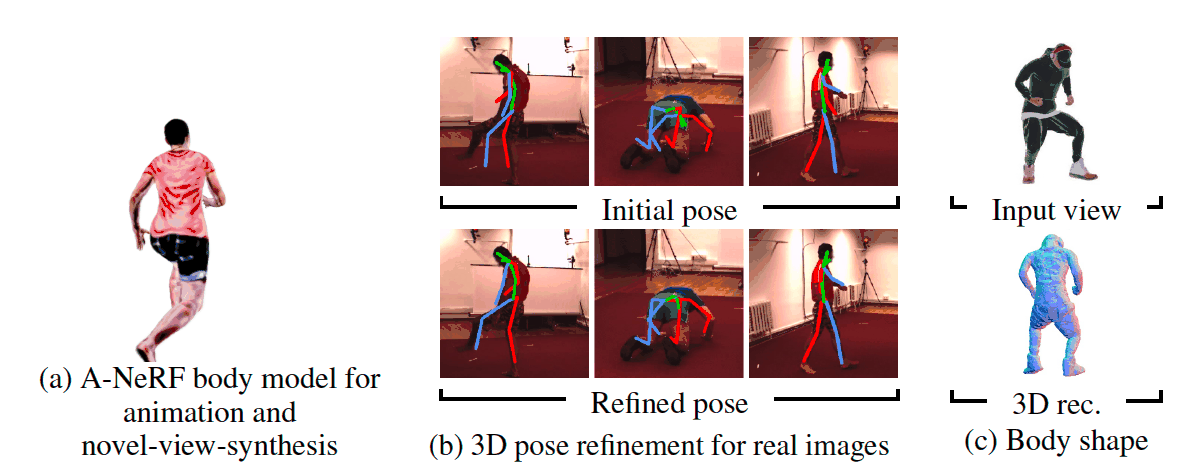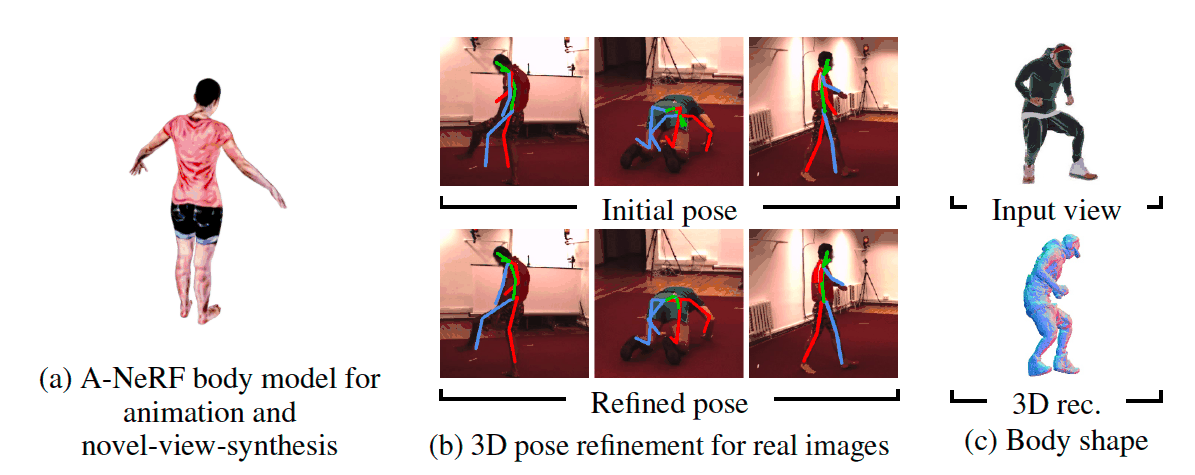
Our A-NeRF jointly learns a neural body model of the user and works with diverse body poses while also refining the initial 3D articulated skeleton pose estimate from a single or, if available, multiple views without tedious camera calibration.
(Left) Articulated human representation learned from synthetic dataset and rendered in unseen poses/novel views.
(Center) Pose refinment on Human3.6M dataset. Faces are blurred out for anonimity.
(Right) 3D reconstruction of A-NeRF body model.
Abstract
While deep learning reshaped the classical motion capture pipeline with feed-forward networks, generative models are required to recover fine alignment via iterative refinement. Unfortunately, the existing models are usually hand-crafted or learned in controlled conditions, only applicable to limited domains. We propose a method to learn a generative neural body model from unlabelled monocular videos by extending Neural Radiance Fields (NeRFs). We equip them with a skeleton to apply to time-varying and articulated motion. A key insight is that implicit models require the inverse of the forward kinematics used in explicit surface models. Our reparameterization defines spatial latent variables relative to the pose of body parts and thereby overcomes ill-posed inverse operations with an overparameterization. This enables learning volumetric body shape and appearance from scratch while jointly refining the articulated pose; all without ground truth labels for appearance, pose, or 3D shape on the input videos. When used for novel-view-synthesis and motion capture, our neural model improves accuracy on diverse datasets.
Overview
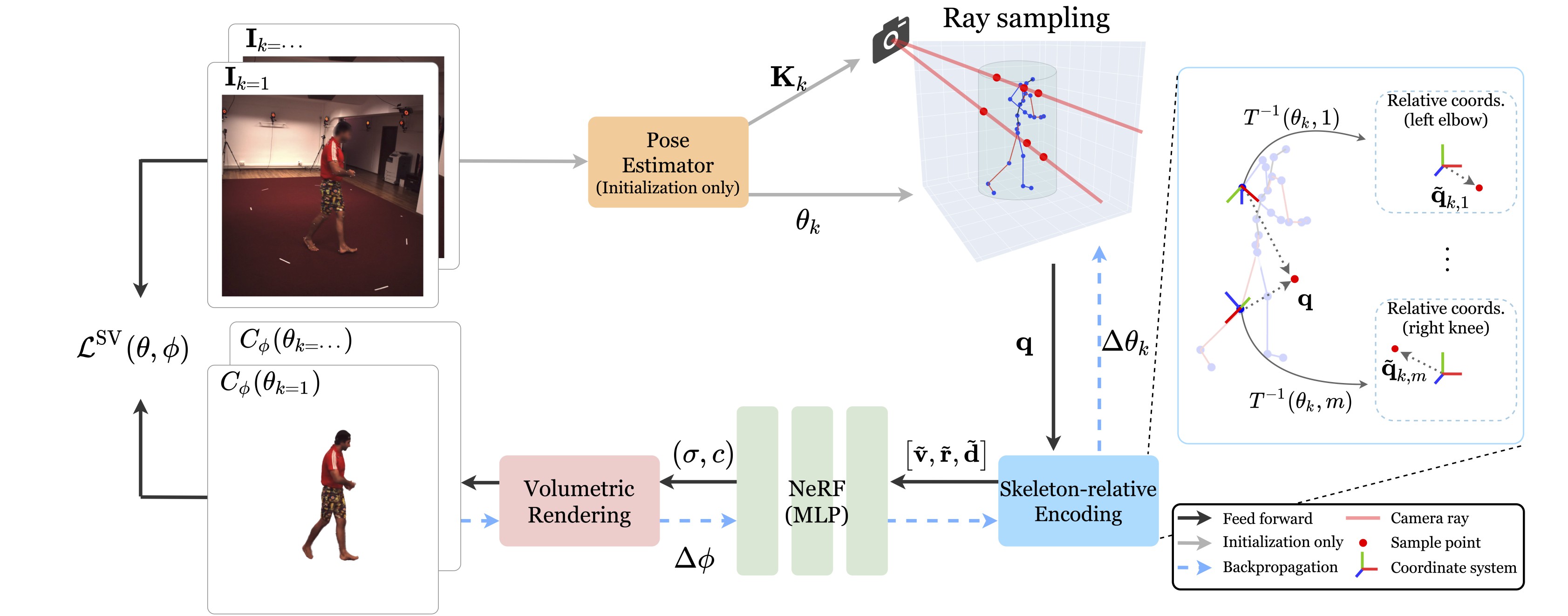
A-NeRF is a generative model that can be rendered and optimized on a photometric loss. First, the skeleton pose is initialized with an off-the-shelf estimator (orange).
Second, this pose is refined via a skeleton-relative embedding (blue) that, when fed to NeRF (green), drives the implicit body model that is rendered by ray-marching (red).
A key property of the skeleton-relative embedding is that a single 3D query location maps to an overcomplete reparametrization, with the same point represented relative to each skeleton bone (right).
Citation
Shih-Yang Su, Frank Yu, Michael Zollhöfer, and Helge Rhodin. "A-NeRF: Articulated Neural Radiance Fields for Learning Human Shape, Appearance, and Pose", NeurIPS, 2021
BibTex
@inproceedings{su2021anerf,
title={A-NeRF: Articulated Neural Radiance Fields for Learning Human Shape, Appearance, and Pose},
author={Su, Shih-Yang and Yu, Frank and Zollh{\"o}fer, Michael and Rhodin, Helge},
booktitle = {Advances in Neural Information Processing Systems},
year={2021}
}